Channeling Away Your PubSub CPU and Memory Usage


We were facing an escalating problem of memory usage that refused to be tamed through horizontal scaling. On closer examination, we discovered that the culprit was none other than our Redis PubSub system that manages multi-user editing, notifications and other websocket-based subscriptions via GraphQL Subscriptions.
I'll take you through how we unraveled our memory issue and found an unexpected solution in sharding our PubSub channels. It's a story that emphasizes the critical importance of understanding the complexities of our chosen tools, and not just accepting the default path. We'll learn about problem-solving, optimization, and the need to keep a sharp eye on performance implications.
The Problem: Rising Memory Usage
As we scaled our application to accommodate a growing user base, we noticed horizontal scaling was not addressing our memory issues.
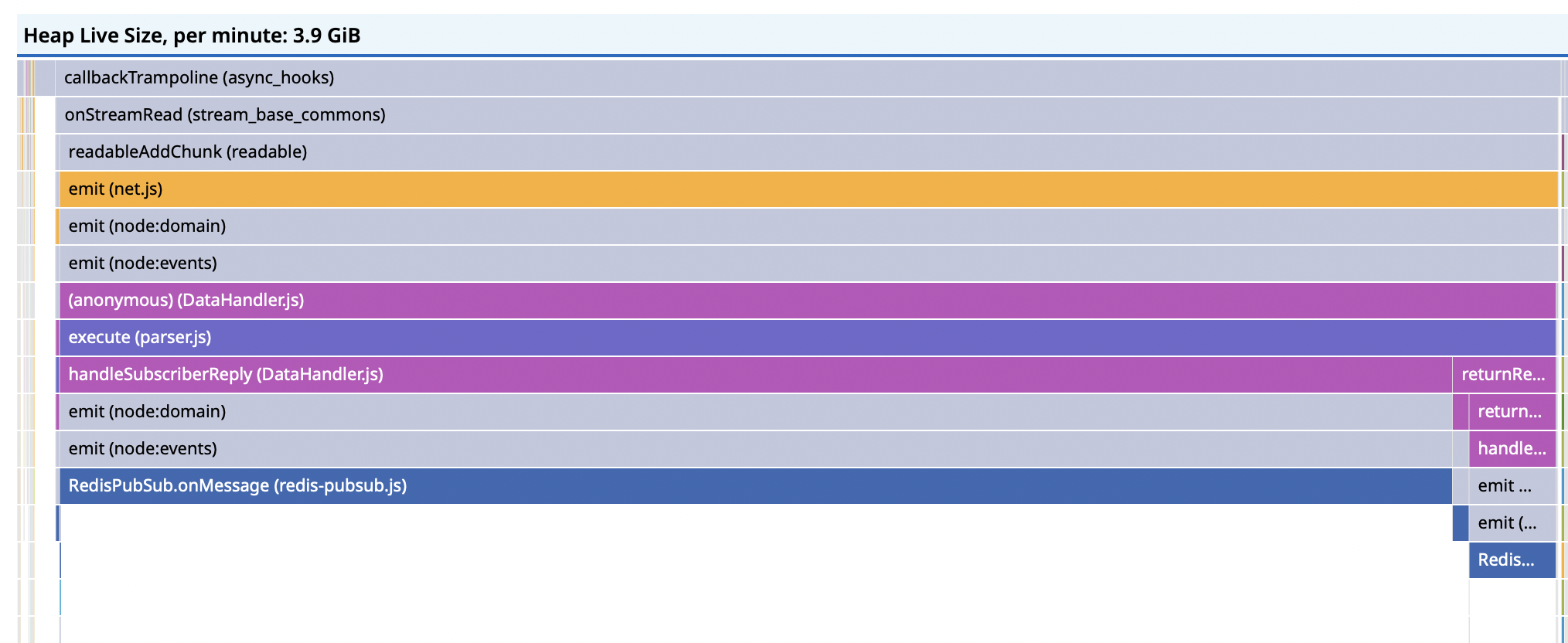
We suspected a memory leak, or perhaps some long running requests to third party services or handling large payloads. We were a little bit in the dark. So we leaned in to some of the offerings from Datadog, namely the continuous profiler.
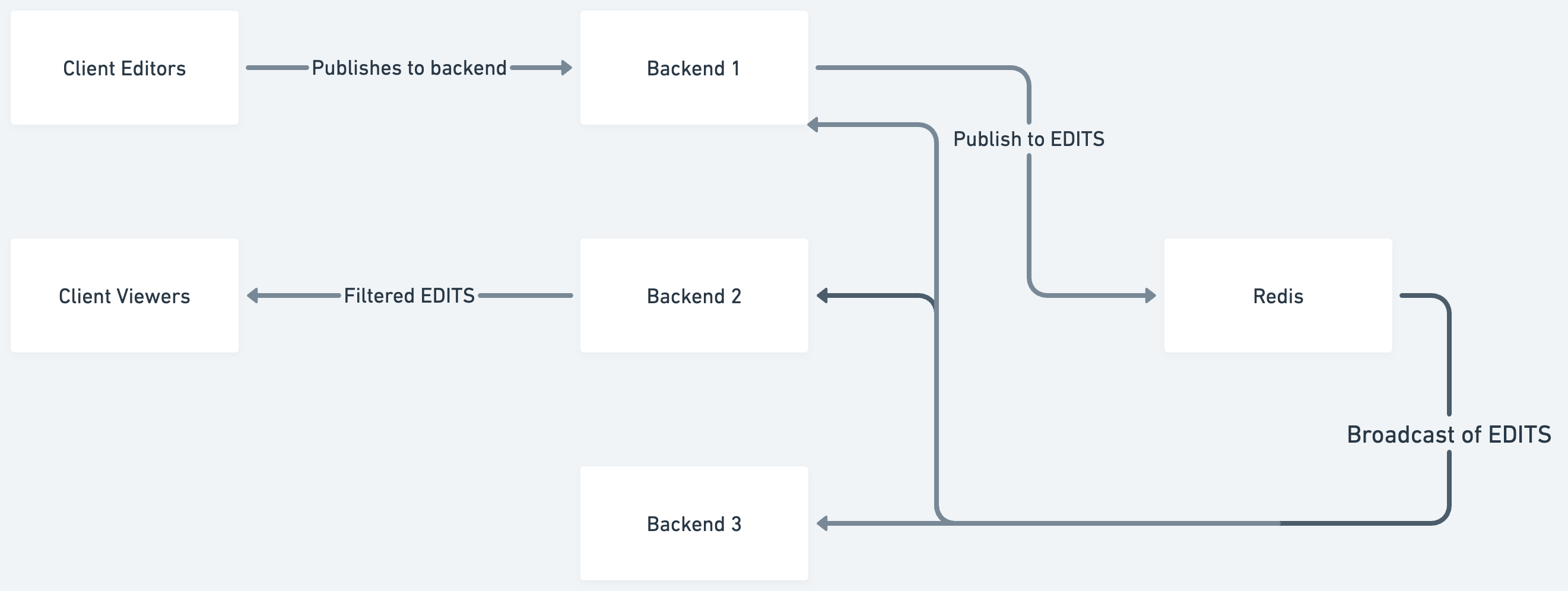
This immediately showed us that the issue was with the Redis PubSub system. PubSub is used to power editing, notifications and other web-socked subscriptions. For example, if someone does a long running task, the backend can send a message to the client that it's done.
Investigating GraphQL Redis Subscriptions
We started using GraphQL Redis Subscriptions when we moved from one backend server to multiple. Prior to that we used Graphql Subscriptions. The latter library maintains subscriptions in-memory and is unique per server. Since we round-robin load-balance a shared Redis made sense.
The documentation for GraphQL Subscriptions suggests we handle subscriptions as follows:
import { withFilter } from 'graphql-subscriptions';
const SOMETHING_CHANGED_TOPIC = 'something_changed';
// These are resolvers for GraphQL
export const resolvers = {
Subscription: {
// This is a resolver or handler for a somethingChanged
// subscription
somethingChanged: {
// This runs a callback to filter results from an iterator that
// redis provides.
subscribe: withFilter(
// The iterator
() => pubsub.asyncIterator(SOMETHING_CHANGED_TOPIC),
// The filter function
(payload, variables) => {
return payload.somethingChanged.id === variables.relevantId;
}
),
},
},
}This uses a single topic, SOMETHING_CHANGED_TOPIC to store all messages. This was fine as we developed our app, but would hurt us as we scaled.
Fundamentally there are two problems:

- We are storing all changes into a single topic and relying on the app to handle the filtering. A real world parallel is if you put all your silverware in a drawer unsorted, you'll need to fish around for a the right utensil each time you need something. Versus putting forks in one spot, spoons in another spot and knives separate, you can quickly grab what you need.
- We are holding in memory all the messages that are in our system, for each subscriber on a single server. Meaning we might have 100 concurrent users to our system, being served by 2 servers. For each user we have a full copy of the stream of subscriptions being held in memory until it can get to the end user. That time is minimal to reach the end user, but it adds up at scale.
1 gives us CPU issues, 2 gives us memory issues. The withFilter becomes O(n^2) problem which will rear its head very suddenly because of exponential growth. We found out that over 99% of the messages would get discarded, and this number would asymptotically reach 100% as our concurrent users grew.
When we moved to the Redis variant of this library, we probably could have revisted the architecture of the channels and split it up then. Being a startup, we weren't really aware that there was a problem so we let that problem grow.
To it's credit, the Redis subscription library documents how to create dynamic channels. While that solution seemed easy and quick to implement as a team we decided to implement some other ideas first.
Filtering Earlier on the Backend
We tackled the second issue first because the risks were fairly minimal and no migration plan was needed.
If we look at the suggested subscription code again:
import { withFilter } from 'graphql-subscriptions';
const SOMETHING_CHANGED_TOPIC = 'something_changed';
// These are resolvers for GraphQL
export const resolvers = {
Subscription: {
// This is a resolver or handler for a somethingChanged
// subscription
somethingChanged: {
// This runs a callback to filter results from an iterator that
// redis provides.
subscribe: withFilter(
// The iterator
() => pubsub.asyncIterator(SOMETHING_CHANGED_TOPIC),
// The filter function
(payload, variables) => {
return payload.somethingChanged.id === variables.relevantId;
}
),
},
},
}We are creating an iterator based on a Redis channel (SOMETHING_CHANGED_TOPIC). This iterator will hold all the messages that have not yet been handed over to the end user in memory.
One of the solutions we came up with involves optimizing the by incorporating the filter function directly into the PubSubAsyncIterator class itself. The primary benefit of this modification is that messages will now be filtered immediately as we build the queue for the user. This cuts down drastically on our load.
Here's what the updated pushValue method looks like:
private async pushValue(event) {
// This kicks off the Redis subscriptions and waits for them
// to complete.
await this.subscribeAll();
// This runs filtering code which early returns if a message
// does not meet the filter requirements
if (this.filterFn) {
const filterResult = await this.filterFn(event, 0);
if (!filterResult) return;
}
// If we get here we add the message to the queue
if (this.pullQueue.length !== 0) {
this.pullQueue.shift()({ value: event, done: false });
} else {
this.pushQueue.push(event);
}
}Now we filter the events as they come in and only if they pass the filter do we add them to the pushQueue.
This change was low risk, it was code that we could easily test in a number of environments and we understood how the filtering works pretty well. The impact was huge as we immediately saw a reduction in memory. We put this feature behind a feature flag as well, so we could roll it out slowly and immediately roll back if we saw customer reports of this not working correctly.
This was so successful that we almost deferred the idea of sharding the channels.
Sharding Channels by ID
While the initial solution of filtering messages earlier on the backend provided significant relief in memory pressure, we knew the single channel situation was wrong. We also were in the thick of the code, so the opportunity cost to fix it now was huge. Lastly, we were worried that we only bought ourselves time. So we decided to shard. There's no magic to this, Graphql Redis Subscriptions outlines how to do this.
Instead of subscribing to SOMETHING_CHANGED we would subscribe to "SOMETHING_CHANGED." + documentId. This reduced the filtering work needed to be done on the backend. In most cases we did not need to provide a filtering function, and could just read directly from the Redis subscription. We even debated backing out our filtering changes, but decided to keep them and also make a pull request with the original project.
While the ultimate code-change was easy, we wanted to be extra careful, so we delicately wrote a migration plan. We wanted to avoid losing edits. We also wanted a way to easily monitor our changes.
Migration Plan
We had a three-phase roll out for three sets of channels.
Set 1. We started with a less popular channel (a job status channel)
Set 2. Once that worked well in production we rolled out to our larger channels (edits)
Set 3. Once the biggest channel was done we were reasonably confident that we could do the rest of our changes together.
Phase 1: Initial Release: Double Read
Redis lets you do multiple subscriptions. So instead of subscribing to SOMETHING_CHANGED or "SOMETHING_CHANGED." + documentId we subscribed to both: ["SOMETHING_CHANGED", "SOMETHING_CHANGED." + documentId]. This meant that our users would get all the messages regardless of where we wrote it. We introduced a flag called SHARD_XYZ_CHANNEL(where XYZ was either JOB, EDITS or ALL) and set it to false. That flag would determine where we would write. When it was false we continued to write to SOMETHING_CHANGED as before. This phase functionally was a no-op even though there was a change in subscription. The risk was minimal because we had tested subscribing to multiple channels quite a bit.
Phase 2: Write to the shard
On an EC2 instance in our VPC we subscribed to the unsharded channels in one terminal pane:
stdbuf -oL redis-cli redis -h pubsub.aws.com SUBSCRIBE SOMETHING_CHANGED | grep SOMETHING_CHANGEDIn another terminal pane:
stdbuf -oL redis -h pubsub.aws.com PSUBSCRIBE SOMETHING_CHANGED:\*|grep SOMETHING_CHANGED:When the flag is off, the first pane is showing us that a lot of data is coming through.
When we flipped our feature flag to true, we immediately saw nothing on the first pane and the second pane became very populated. This was fairly crude, but it was a quick safety check that what we intended to happen happened.
We also had Datadog metrics and dashboards that could show us new channels were generating data. More on that outcome later.
Phase 3: Cleanup
Once we had run our code with sharded channels for a while we could safely remove all our code that relied on the feature flag.
This was a lot of extra steps, but we knew that our customers would not be happy if they were in the middle of editing a document. So we were determined to be careful. Every change here was executed locally and in a staging environment before production rollout.
Monitoring
Monitoring was a crucial part of our migration plan. In fact, we had started monitoring before the sharding migration as a way of validating that we needed to do this work.
We monitored:
- Topics/Channels - we wanted to see this increase. This was done manually via Redis, but we also could see what we were reading after migration. This went up as expected, but the absolute number of channels stayed fairly constant. Channels disappear when there are no subscriptions.
- We wanted to monitor our overall app health, we had existing dashboard for that. Nothing changed as predicted
- We expected to see memory and CPU fall. It plumeted. We realized "scaling out of every problem" was no longer necessary and we were way over provisioned both in host count and memory usage.
We also noticed our network traffic went down. Internal VPC traffic isn't a metric we normally look at but we decided to see if anything changed and it similarly plumeted. This was not a primary goal, but network activity can be limited by instance types, so it's nice to know that wasted data isn't being transmitted.
Between long-running monitors and open terminal windows, we were pretty confident the changes we made were beneficial and not at all an impact to our users.
Lessons Learned
- Collaborate with your team: There were multiple people who worked on this issue. Each of us had our own takes on what things would be beneficial and we triaged and agreed as a team what steps to take and in what order. I know personally I had some biases against some of our external API calls, but it turned out those weren't the problem.
- Think through complexity and tools: We added GraphQL Subscriptions very early on into our app maybe double digits of concurrent users. Big-O doesn't matter, but if the
ncan grow unbounded, and often it's not a planned event. This also means understanding the nuances of how your tools work. Most of us understood how PubSub worked, but not Redis specifically, but it wasn't hard to get up to speed. - Test everything: We have a complex system, but luckily we have a suite of end to end tests that rely on critical portions like Redis being in place. Additionally nothing is more comforting than manual testing in non production environments. This made us confident that our changes were effective. We could also inspect any of our changes.
- Monitor everything: As mentioned before, we had extensive monitoring in place. This was invaluable in identifying any potential issues early and making sure the system was performing as expected after the migration.
- Use a phased approach: Rolling out changes in phases allowed us to verify the correctness of our strategy and minimize the impact on our users. It also gave us the opportunity to rollback swiftly if needed.
In the end we learned that at scale we need to understand in detail the libraries and infrastructure we use with a greater degree of depth. By digging into the complexities of the Redis PubSub system and GraphQL Subscriptions, we were able to pinpoint the root cause of the problem and devise a solution that not only resolved the issue but also significantly improved the performance of our application.
We also found another scaling bottleneck. Horizontal scaling would never solve this problem, not for too long. It requires finding the inefficiencies in our code and infrastructure.
We also learned the value of thorough testing, monitoring, and phased rollouts in ensuring a smooth and successful implementation of changes. These are pillars of our strong engineering culture. Incidents like this further justify these principles.
If you want to chat some more about this, send me an email pubsuboverload@davedash.33mail.com.