Retweeting Robot


San Jose tweets their updates in multiple languages:
Help out. If you’d like to support wildfire evacuees, please contribute to the Silicon Valley Community Foundation Fire Relief Fund. To donate, visit: https://t.co/YIV2w9lfua #SCULighteningComplex
— City of San José (@CityofSanJose) August 23, 2020
Ayude. Si desea apoyar a los evacuados por incendios, por favor contribuye al Fondo de Ayuda para Incendios de la Fundación Comunitaria de Silicon Valley. Para donar, visite: https://t.co/YIV2w9lfua. #SCULightningComplex
— City of San José (@CityofSanJose) August 23, 2020
Which is great, because it can pull in more people who aren't fluent in English, but it can clutter up the timeline.
So I wanted to create a Twitter bot that could read tweets from @CityofSanJose and retweet the ones in English. So I figured I'd need a new Twitter account, a library that talks to Twitter and a library that can detect written languages.
The Lab Work
I decided to use python because I could use my favorite tool, Jupyter Lab. Jupyter Lab lets me see my code do things as I write it, which suits my style of coding.
$ pipenv install --dev jupyterlab
$ pipenv run jupyter labIf you don't have a great python setup, I really like Jacob Kaplan Moss's environment.
From a new Notebook I was able to muck around with the API. I could even install libraries that seemed helpful.
!pipenv install python-twitter
!pipenv install python-dotenv # So I could put my API keys somewhere safe.
!pipenv install langdetect # A language detection librarySo the python-twitter library is nice, because it has methods to get everything I need. To get all the tweets:
statuses = api.GetUserTimeline(screen_name='cityofsanjose', include_rts=False, count=100)I decided to fetch a lot, because San Jose can tweet as many as 5 different languages. So 100 tweets may have only 20 tweets in English.
Language Detection
I decided to peek at the language detection:
from langdetect import detect, detect_langs;
for status in statuses:
if not detect(status.text) == 'en':
continue;
print(detect_langs(status.text));
print(status.text);This looked mostly okay but for a few miscategorizations:
[en:0.42858316279530484, vi:0.4285695383927767, ca:0.142844938956811]
目前CalFire尚未在#SanJose市內發布任何警告或疏散命令。 通過訪問來為迅速變化的條件做好準備 https://t.co/6e6DffhHlU. #SCULightningComplex
[en:0.5714279652071645, no:0.2857136829087986, vi:0.142856509207218]
目前CalFire尚未在#SanJose市内发布任何警告或疏散命令。 通过访问来为迅速变化的条件做好准备https://t.co/6e6DffhHlU. #SCULightningComplexLuckily the langdetect gives me a little more to work with (like additional scoring you see). It's totally reasonable that the English words in this otherwise Chinese tweet confused the machine. Unfortunatetly I'm not sure the second and third place languages were much help.
I don't know an easy way to fix this, but I know how to write failing tests. So that's where I began. It was also enough of a signal that a text had potentially multiple options that it was not English.
import pytest
from retweeter.helpers import probably_english
NOT_ENG='目前CalFire尚未在#SanJose市內發布任何警告或疏散命令。 通過訪問來為迅速變化的條件做好準備 https://t.co/6e6DffhHlU. #SCULightningComplex'
NOT_ENG2='目前CalFire尚未在#SanJose市内发布任何警告或疏散命令。 通过访问来为迅速变化的条件做好准备https://t.co/6e6DffhHlU. #SCULightningComplex'
ENG='As of 8/21/20 at 11:00 a.m., CalFire has issued no warning or evacuation order within the City of San Jose. Be prep… https://t.co/5NWroKwRjV'
@pytest.mark.parametrize('text,expected', [(NOT_ENG, False), (NOT_ENG2, False), (ENG, True)])
def test_probably_english(text, expected):
assert(probably_english(text)) == expected
Okay so a naive way that might work most of the time is finding anything that has a possibility of not being English should just discount it entirely. I'd rather have too few tweets than too many.
def probably_english(text):
langs = detect_langs(text)
if langs[0].lang == 'en' and len(langs) == 1:
return True
return FalseIt passes the test (most of the time, detect_langs is non-deterministic, there's a way to fix that).
So let's peek at the lab again.
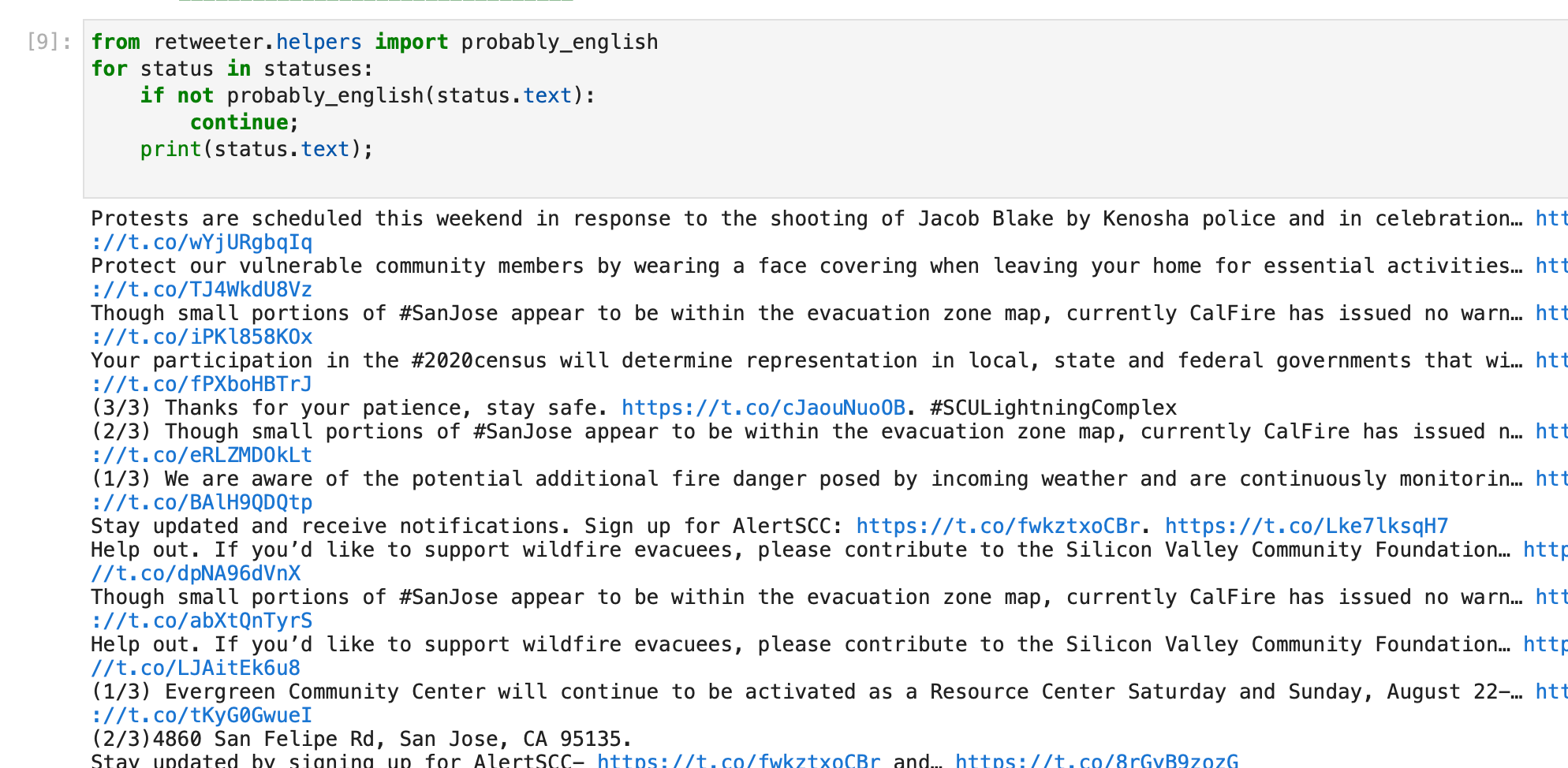
This looks good. If we wanted to be thorough we could audit the tweets, or at the very least look at the subtracted tweets, but we can make that an exercise for later. I'd rather see this launch.
Retweeting
Retweeting with this python API is straightforward:
api.PostRetweet(status.id);This is fine, but if I post a second time I'll run into errors. Which is fine, but I can avoid these errors by only retweeting new posts.
In order to find new posts we need to look at the last thing(s) I retweeted. This method seems promising GetUserRetweets
rts = api.GetUserRetweets();
last_id_retweeted = rts[0].retweeted_status.idBut upon closer inspection, I found a bug. The statuses arrive in reverse-chronological order (expected), so when I retweet-them it posts the timeline backwards. I'll need to reverse the statuses before I retweet:
statuses.reverse();
for status in statuses:
if not detect(status.text) == 'en':
continue;
api.PostRetweet(status.id);Let's go back to our GetUserTimeline and give it our last_id_retweeted.
statuses = api.GetUserTimeline(screen_name='cityofsanjose', include_rts=False, count=100, since_id=last_id_retweeted)Now all our statuses should be new ones that we haven't seen (with the exception of a few statuses that aren't in English that we previously ignored).
Cleanup the Lab
The beauty of using Jupyter Lab is I can write things as it comes to my head in the most stream of conscience way. Then I delete all the print statements and the inspections of elements. Then I rearrange the code to flow logically. Finally I can replay the whole code to verify that it works.
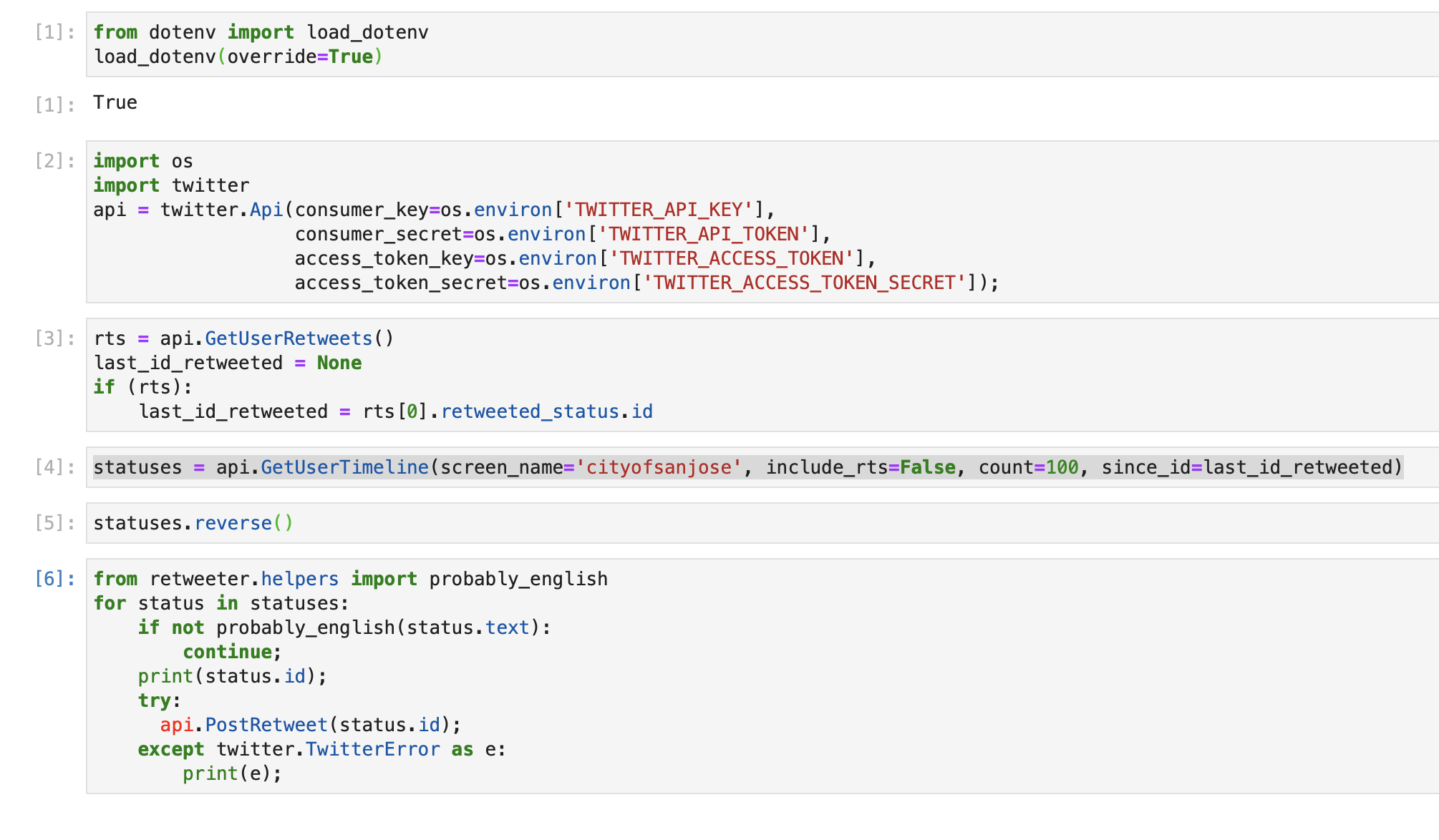
It's a fairly straightforward script. I can even merge them into a single cell for the best copy-paste experience. Here's the proper .py file.
Launch Time
Heroku can be free-ish. Let's use that. I created a heroku app and installed the scheduler add-on. I installed whatever environment variables I needed for the twitter API calls:
heroku config:set $(cat .env)
I wanted an easy one-liner script, so I used make. Here's a Makefile:
install:
pipenv install
run: install
pipenv run python main.pyIt worked on my commandline and I pushed it to heroku. Verified that it works in the ☁️ :
heroku run make run
I did set a Procfile with a line clock: make run. I didn't use it other than to let Heroku know I want to use the free tier.
Now in the scheduler admin (heroku addons:open scheduler) I added a schedule to run make run every 10 minutes.
I tailed the logs and watch it do it's business.
Resources
Feel free to subscribe to my bot: https://twitter.com/cityofsanjoseEN
You can look at my work here on Github:
 davedash
davedash
If you are stuck, have ideas, or have a bot to share email me retweeting@davedash.33mail.com.